Transform Runs to Datasets
Horreum stores data in the JSON format. The raw document uploaded to repository turns into a Run, however most of operations and visualizations work on Datasets. By default there’s a 1-on-1 relation between Runs and Datasets; the default transformation extracts objects annotated with a JSON schema (the $schema property) and puts them into an array - it’s easier to process Datasets internally after that. It is possible to customize this transformation, though, and most importantly - you can create multiple Datasets out of a single Run. This is useful e.g. when your tooling produces single document that contains results for multiple tests, or with different configurations. With the Run split into more Datasets it’s much easier to display and analyze these results individually.
We assume that you’ve already created a test, uploaded some data and defined the Schema.
In this example we use test acme-regression with the basic schema urn:acme-schema:1.0 and uploaded JSON:
{
"$schema": "urn:acme-schema:1.0",
"testName": ["Test CPU1", "Test CPU2", "Test CPU3"],
"throughput": [0.1, 0.2, 0.3]
}
Defining a Transformer
Here we will show how to define the transformation from the raw input into individual Datasets so that each testName and throughput goes to a separate set.
As the structure of the documents for individual tests (stored in Dataset) differs from the input document structure (urn:acme-schema:1.0) we will define a second Schema - let’s use the URI urn:acme-sub-schema:1.0.
Back in the acme-schema we switch to Transformers tab and add a new CpuDatasetTransformer. In this Transformer we select the acme-sub-schema as Target schema URI: the $schema property will be added to each object produced by this Transformer. An alternative would be setting the target schema manually in the Combination function below. Note that it is vital that each Transformer annotates its output with some schema - without that Horreum could not determine the structure of data and process it further.
We add two extractors: testName and _throughput_that will get the values from the raw JSON object. These values are further processed in the Combination function. If the function is not defined the result will be an object with properties matching the extractor names - the same object as is the input of this function.
As a result, the transformer will return an array of objects where each element contributes to a different DataSet.
Transformer Setup
Use transformers in the test
Each schema can define multiple Transformers, therefore we have to assign our new transformer to the acme-regression test.
Tests > Transformers
Test Transformers
After Saving the test press Recalculate datasets and then go to Dataset list to see the results. You will find 3 Datasets, each having a separate test result.
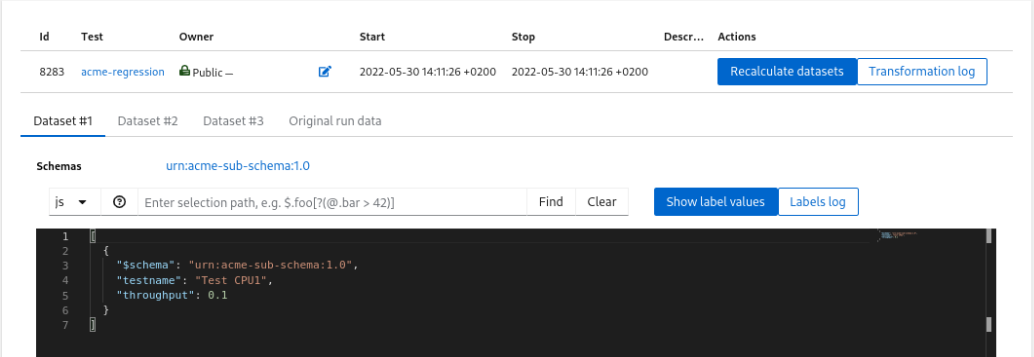
Datasets
Use labels for the fingerprint
When you’ve split the Run into individual Datasets it’s likely that for purposes of Change Detection you want to track values from each test individually. Horreum can identify such independent series through a Fingerprint: set of labels with an unique combination of values.
Go to the acme-sub-schema and define the labels testname and throughput: the former will be used for the Fingerprint, the latter will be consumed in a Change Detection Variable.
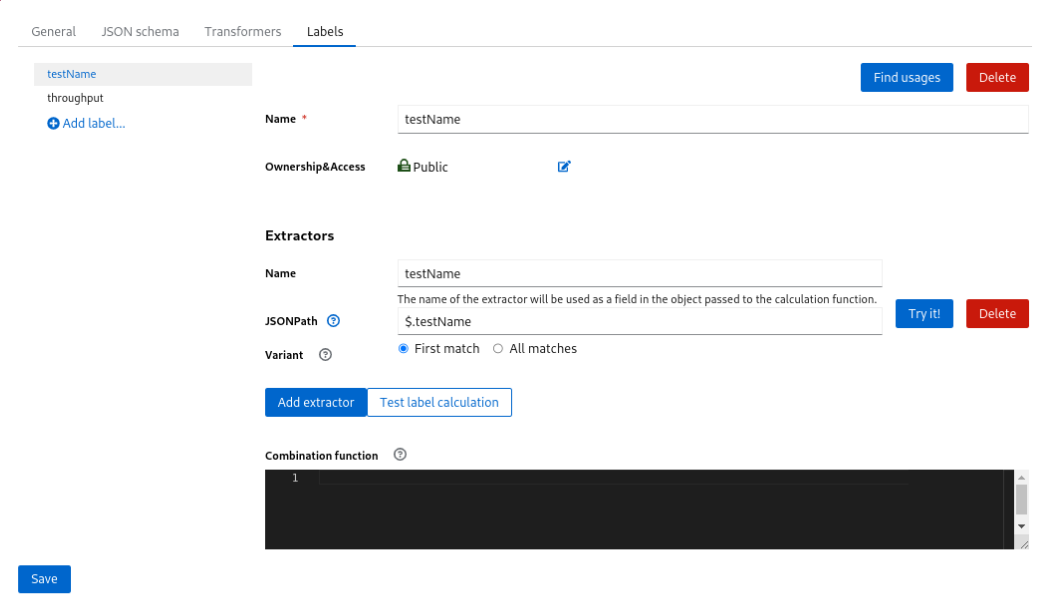
Labels
Then switch to Test > Change detection and use thos labels. The Fingerprint filter is not necessary here (it would let you exclude some Datasets from Change detection analysis.
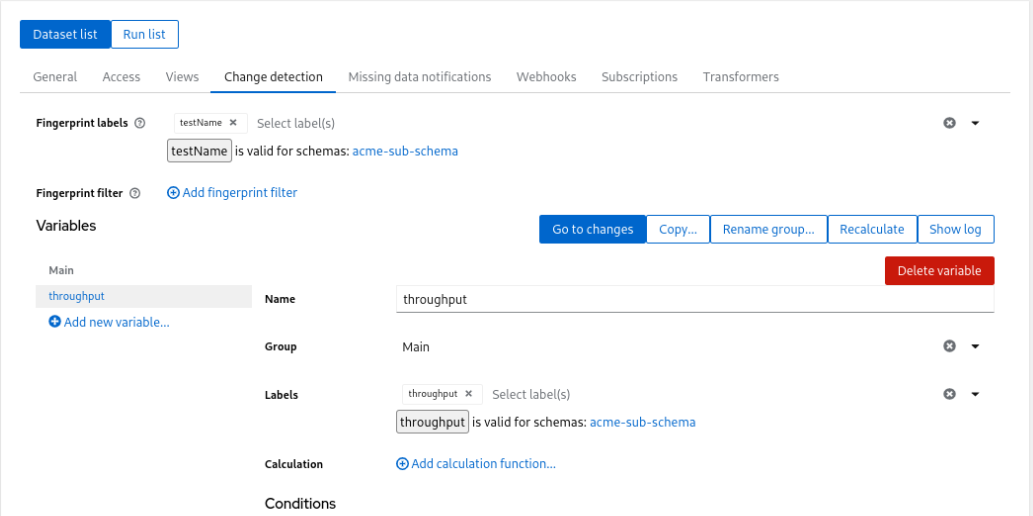
Variables
After saving and recalculation you will see the new data-points in Changes
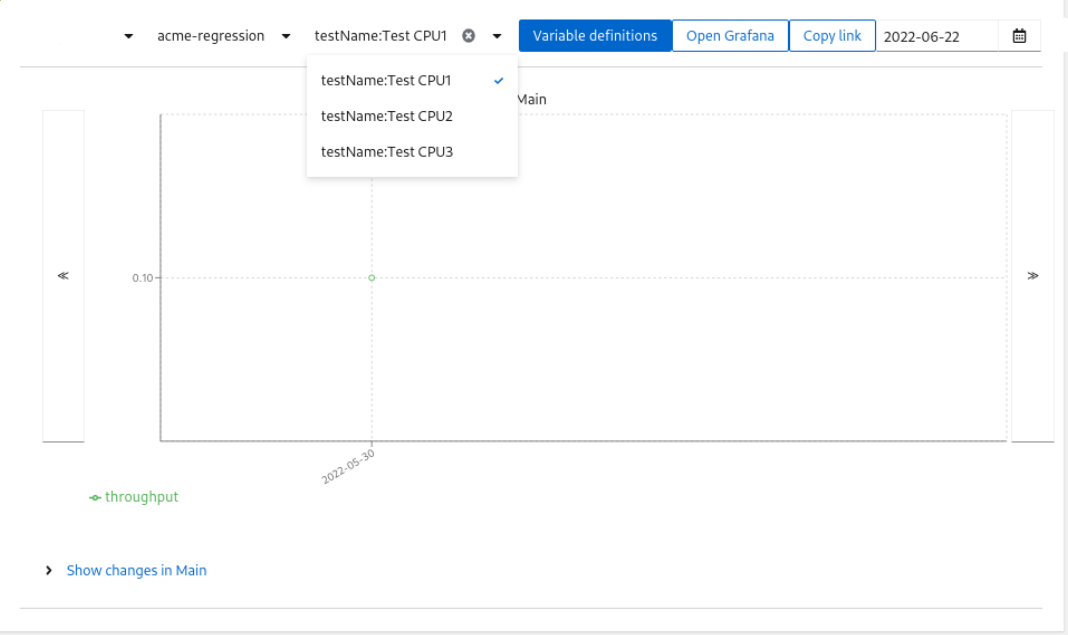
Change
In this guide we transformed the Run from the batch results arrays to individual Datasets. Then we extracted data using Labels and them for Change detection.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.